|
( Branko Soric: ZNANOST NIJE STATISTICKI DOVOLJNO PROVJERENA - Zagreb,III.-
V. 2001.)
---- II. DIO
5. Sto treba uciniti kada Qmax nije dovoljno malen?
Pretpostavimo da smo za vrlo velike
skupove n i r dobili Qmax = 0,4 . U tom slucaju alternativne hipoteze ne mogu se prihvatiti, odnosno, drugim rijecima, nemamo
opravdanja da otkrica u skupu r smatramo istinitim otkricima, jer u tom skupu stvarno moze biti cak do 40% laznih otkrica.
Ali, buduci da stvarna proporcija laznih otkrica (Q) moze biti manja od Qmax (Q<Qmax), u skupu r moze biti i mnogo istinitih
otkrica. Zato taj skup ne treba definitivno odbaciti, nego je POTREBNO DALJNJE PROVJERAVANJE.
To provjeravanje moze se
izvrsiti na dva nacina:
Jedan nacin je taj, da se ponove (mnogi ili svi) pokusi koji su prethodno dali veliki skup
od r znacajnih rezultata. Tim ponavljanjem dobiti ce se novi (nesto manji) skup znacajnih rezultata (koji mogu biti znacajni,
na pr., na istoj razini kao i prije). U tom novom skupu biti ce manja proporcija (manji postotak) laznih otkrica, t.j. biti
ce manja (nepoznata) vrijednost Q, a racunanjem ce se dobiti i nova, manja vrijednost Qmax. (Ako je prethodna vrijednost bila,
na pr., Qmax = 0,4 nova vrijednost ce biti manja od 0,4. Ako ta nova vrijednost Qmax jos uvijek nije manja od 0,05 moze se
izvrsiti jos jedno ponavljanje cijelog (novog) skupa pokusâ. Kod tih ponavljanja pokusâ dobro je uzeti i vece uzorke nego
prije).
Drugi nacin provjeravanja je ponavljanje samo pojedinih pokusa (na pr. onih koji su nam narocito zanimljvi)
na VECIM UZORCIMA. Ako smo prethodno, na manjim uzorcima, postigli razinu p<0,05 ili p<0,01 tada cemo, u slucaju da
doista postoji znatan efekt, na vecim uzorcima lako postici mnogo visu razinu znacajnosti, koja ce nam mozda omoguciti odbacivanje
nul-hipoteze u takvom POJEDINACNOM pokusu. To ce biti moguce, ako se postigne vrlo mala vrijednost p, na pr.
p<10^-9,
a cini se da bi mogla biti dovoljna i vrijedmost
p<10^-6 = 0,000001 (kao sto ce biti nize objasnjeno - vidi 6.1).
Postizanje
ekstremno visokih razina znacajnosti (na pr., p<10^-9,
ili p<10^-12, p<10^-15, itd.) vazno je i radi mogucnosti
procjene
velicine efekta (velicine razlike medju populacijama). (Vidi nize: 5.2).
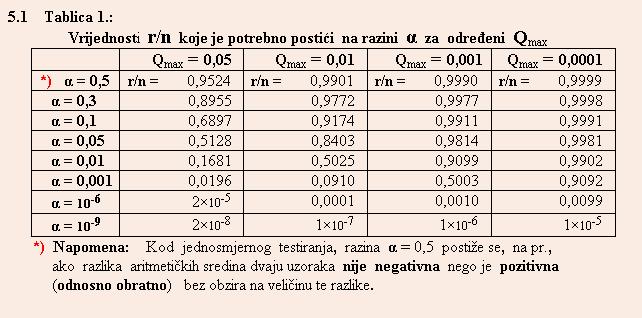
5.2 Velicina efekta i intervali pouzdanosti
---(Napomena: Ovdje uvijek
govorimo o jednostranim intervalima i jednosmjernom testiranju).
Kao sto je gore receno, postizanje ekstremno visokih
razina znacajnosti vazno je i radi mogucnosti procjene velicine efekta (velicine razlike medju populacijama).
Neki pogresno
misle, da se u slucaju otkrica t.j. u slucaju znacajne razlike dobivene na uzorcima (p<0,05 ili p<0,01, ili slicno,
a bez poznavanja omjera r/n) moze odrediti velicina efekta sa 95-postotnom odnosno 99-postotnom "pouzdanoscu" - tako da se
izracunaju odgovarajuci "intervali pouzdanosti" odnosno "granice pouzdanosti".
To je zabluda, jer U SKUPU OTKRICA lako
moze biti daleko vise od 5% (odnosno od 1%) pogresnih intervalnih procjena! (Naime, uporabom tih intervala pouzdanosti, u
velikom skupu od n pokusa dobivamo 0,05×n odnosno 0,01×n pogresnih procjena, koje sve odgovaraju statisticki znacajniom rezultatima,
tako da u r znacajnih rezultata postoji ¤n (=alfa×n) pogresnih procjena. Ako tu proporciju pogresnih procjena oznacimo slovom
E, tada je E = ¤n/r > Qmax. [Vidi ranije objavljeni rad: Soric B.: "Statisitcal 'Discoveries' and Effect-size Estimation",
Journal of the American Statistical Association, Vol. 84, no. 406 (Theory and Methods), 1989, str. 608-610.).]
Dakle,
proporcija (E) pogresnih intervalnih procjena efekta u skupu od r statisticki znacajnih rezultata ovisi o postignutom omjeru
n/r odnosno r/n, a o tom omjeru ovisi i Qmax . Ako bismo uz razinu ¤=alfa=0,05 postigli otkrica u svim pokusima (t.j. r/n
= 1), samo tada bi 95-postotni intervali pouzdanosti dali 5% pogresnih procjena efekata u r otkricâ, dok bi Qmax bio jednak
nuli. Za druge vrijednosti r/n, uz istu razinu ¤=alfa=0,05 , dobije se:
Za r/n =0,9.....:..... Qmax = 0,006......t.j.
0,6%........E = 0,056....t.j. 5,6%;
za r/n =0,5..... :..... Qmax = 0,053......t.j. 5,3%........E = 0,1........t.j. 10%;
za r/n =0,2......:..... Qmax = 0,211......t.j. 21,1%......E = 0,25......t.j. 25%;
za r/n =0,1......:..... Qmax = 0,474......t.j.
47,4%......E = 0,5........t.j. 50%;
za r/n =0,051..:..... Qmax = 0,979......t.j. 97,9%......E = 0,98......t.j. 98%;
za
r/n =0,05....:..... Qmax = 1,000......t.j. 100%........E = 1,00......t.j. 100%
Kako se moze procijeniti velicina efekta
u slucaju vrlo visoke statisticke znacajnosti pokazuje slijedeci primjer:
Pretpostavimo da od neke bolesti umire (bez
lijecenja) 20% bolesnika, a u ispitivanju je od 5000 lijecenih bolesnika umrlo 700 t.j. 14%. Rezultat je statisticki ekstremno
znacajan:
p< 4,5×10^-25 (*) ili tocnije: p = 3×10^-26 (**) (Vidi nize napomenu!).
Odatle zakljucujemo da razlika
medju populacijama mora biti veca od nule, t.j. prakticki smo sigurni da uz lijecenje umire manje od 20% bolesnika; ali, KOLIKO
manje?
Ako pretpostavimo da bi u cijeloj populaciji uz lijecenje umrlo 17% bolesnika, pa to usporedimo sa dobivenim
rezultatom na uzorku (700 umrlih od 5000), jos uvijek cemo dobiti visoko znacajan rezultat:
p<1,3×10^-7 (*) ili tocnije:
p = 2×10^-8 (**) (Vidi nize napomenu!).
Dakle, ako odbacimo ne samo nul-hipotezu (po kojoj bi umiralo 20% lijecenih
bolesnika, isto kao i nelijecenih) nego i hipotezu o 17% umrlih lijecenih bolesnika, zakljucujemo da uz lijecenje umire manje
od 17% bolesnika, tako da se tim lijecenjem spasava vise od 3% oboljelih. Na taj smo nacin saznali da je EFEKT ne samo veci
od nule nego je VECI OD 3%.
.............................................................................................................
Napomena: U gornjem primjeru upotrebljen je hi-kvadrat test. Postoji JEDAN stupanj slobode, te se racunanjem dobivaju
vrijednosti koje su gore oznacene dvjema zvjezdicama (**). Medjutim, zbog ekstremno visokih postignutih razina znacajnosti,
do istih zakljucaka dolazimo i na temelju nesto vecih vrijednosti p koje su gore oznacene jednom zvjezdicom (*), a koje su
izracunate po formuli za DVA stupnja slobode; naime, ta formula omogucava lakse racunanje:
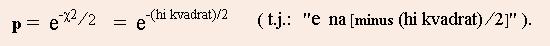
Kao sto se gore vidi, prave vrijednosti p za
jedan stupanj slobode (**) manje su od onih koje su oznacene jednom zvjezdicom (*) a koje su dobivene po navedenoj formuli.
Dakle, kad postoji jedan stupanj slobode, mozemo pokusati izracunati p po formuli za dva stupnja slobode, pa ako dobijemo
dovoljno mali p, tada znamo da je prava vrijednost p jos manja.
6. Izracunavanje Q'1max i Q'2max po formuli (2) i
(3)
----(Izvod formule (2) i (3) nalazi se u DODATKU D).
Prije vise godina, u dva navrata, prebrojavao sam objavljene
znacajne rezultate u nekim brojevima Lijecnickog vjesnika:
ISPITIVANJE 1. : U DESETAK uzastopnih brojeva Lijecnickog vjesnika
iz 1983.-84. godine nasao sam sest rezultata sa postignutom razinom znacajnosti p<0,000001 = 10^-6 (premda su autori naveli
razine od p<0,05 do p<0,001). Na zalost, te brojeve Lijecnickog vjesnika nisam sacuvao, pa ne znam koliki je bio ukupan
broj znacajnih rezultata (na razini p<0,05 ili visoj), ali imam zapisana imena autorâ i vrijednosti p za spomenutih sest
radova:
Medved R.:.....objavljeno: p<0,05;...stvarno postignuto: p<10^-15
Durakovic Z.:..objavljeno: ....---....;...stvarno
postignuto: p<10^-15 (p=10^-38)
Posinovec J.:...objavljeno: p<0,01;....stvarno postignuto: p<10^-15 (p=10^-66)
Matulic Z.:.......objavljeno: p<0,001;..stvarno postignuto: p<10^-6
Lederer V.:......objavljeno: p<0,05;....stvarno
postignuto: p<10^-6
Presecki V.:.....objavljeno: p<0,001;..stvarno postignuto: p<10^-6
ISPITIVANJE 2.:
Nekoliko godina kasnije, nasao sam jos DESET (drugih, preostalih) brojeva Lijecnickog vjesnika iz 1983.-84. godine te DEVET
brojeva iz 1985. godine (svi su izabrani nasumce, t.j. slucajno su nadjeni u ormaru). U tih 19 brojeva bilo je 116 objavljenih
vrijednosti p<0,05 OD KOJIH je u 84 slucaja ta vrijednost bila p<0,01. (Napomena: Skup r2 je podskup skupa r1). Dakle:
r1 = 116 (za razinu ¤1 = 0,05);.......r2 = 84 (za razinu ¤2 = 0,01);
r1/r2 = 1,381 ;........ r2/r1 = 0,724
Medjutim,
u znatnom broju tih radova bilo je objavljeno po nekoliko vrijednosti p u istom clanku, t.j. usporedjivale su se, u istom
istrazivanju, razne velicine, koje su mogle biti medjusobno ovisne, pa se nije radilo o zasebnim, nezavisnim pokusima. Zato
sam, naknadno, u svakom radu uzeo u obzir samo po jednu objavljenu razinu znacajnosti, i to onu najvisu (najmanji p). [Napomena:
U nekim radovima objavljena je razina p<0,05 premda je stvarno postignuta visa razina p<0,01. U takvim slucajevima uzeta
je u obzir ta visa razina znacajnosti].
Na taj nacin dobio sam:
r1 = 27 (za razinu ¤1 = 0,05);....... r2 = 23 (za
razinu ¤2 = 0,01);
r1/r2 = 1,174 ;...... r2/r1 = 0,852
Te vrijednosti r su PREMALENE za izracunavanje proporcija Q'1max
i Q'2max ali pogledajmo ipak kakve bismo rezultate dobili, kada bismo nasli jednake odnose u vecim skupovima r.
Pretpostavimo
da bismo pregledali radove, objavljene kroz 10 ili 20 godina u vise desetaka raznih znanstvenih casopisa, te da bismo nasli
1000 puta vece brojeve znacajnih rezultata (r1 i r2), uz isti omjer r1/r2 = 1,174. Dakle::
r1 = 27000 (za razinu ¤1 =
0,05);..... r2 = 23000 (za razinu ¤2 = 0,01);
r1/r2 = 1,174 ;...... r2/r1 = 0,852
Priblizni rezultati, dobiveni po
formuli (2) i (3), su ovi:
Q'2max = 0,0435 < 0,05....i....Q'1max = 0,1852
Vrijednost Q'2max (=0,0435 za razinu
¤2 = 0,01) bila bi zadovoljavajuca (t.j. manja je od 5%), dok bi vrijednost Q'1max (za razinu ¤1 = 0,05) znacila, da je potrebno
na drugi nacin provjeriti koliki je zapravo postotak laznih otkrica na razini 0,05.
[NAPOMENA: "Najvecu mogucu" vrijednost
za Q'2max mozemo izracunati na nacin
koji je prikazan pod 4.2:
Polazimo od toga da, u najgorem slucaju, postoji r1
= 27000 laznih otkrica na razini ¤1 = 0,05 , medju kojima se ocekuje 5400 laznih otkrica na razini ¤2 = 0,01 (naime: 27000×0,2
=5400 , jer se proporcije laznih otkrica medjusobno odnose kao vjerojatnosti znacajnosti t.j.:
¤2 : ¤1 = 0,01 : 0,05 =
0,2 = 5400 : 27000).
Medjutim, broj laznih otkrica na razini 0,01 moze slucajno biti i veci, ali prakticki ne moze biti
veci od 5795 (uz vjerojatnost od 10^-9, t.j. jedan naprama milijardu, da bi ipak bio veci). Odatle nalazimo broj istinitih
otkrica na razini 0,01 (t.j. 23000-5795 = 17205), zatim novi broj laznih otkrica na razini 0,05 (t.j. 27000-17205 = 9795);
pa onda novi ocekivani broj laznih otkrica na razini 0,01 (t.j. 9795×0,2 = 1959) koji prakticki ne moze biti veci od 2197
(uz vjerojatnost od jedan naprama milijardu da bi bio veci), itd., itd. Konacno nalazimo da je "najveca moguca" proporcija
laznih otkrica: Q'2max = 1217/23000 = 0,0529 (to bi bilo prilicno zadovoljavajuce, jer je samo malo vece od 0,05); (Q'1max
= 0,2254)].
6.1 Koja razina znacajnosti je dovoljno visoka u pojedinacnom pokusu?
Pretpostavljam da ce se
gotovo svatko intuitivno sloziti, da je SVAKAKO DOVOLJNO postici p<10^-9 (t.j. p manji od jedan naprama milijardu) da bi
se odbacila nul-hipoteza u pojedinacnom pokusu.
Taj bi se kriterij mogao i objektivnije opravdati; na pr., ako bi se u
Lijecnickom vjesniku objavilo godisnje cak 1000 (= r1) znacajnih rezultata (p<0,05 = ¤1) postignutih u nezavisnim pokusima,
te ako bi se u deset godina pojavio samo jedan rezultat znacajan na razini ¤2 = 10^-9, t.j. godisnje (prosjecno) r2 = 0,1
, nasli bismo (po formuli (2) za Q'2max) da je maksimalna proporcija laznih otkrica:
Q'2max = 0,0002.
MEDJUTIM,
AKO POSTIGNEMO p=0,000001 (jedan naprama milijun), JE LI TO TAKODJER DOVOLJNO VISOKA RAZINA za odbacivanje nul-hipoteze u
pojedinacnom pokusu?
Mogli bismo pretpostaviti (za razliku gore navedenoga) da je r1 ipak manji od 1000 znacajnih rezultata
(prosjecno, godisnje). Na pr.:
r1 = 100 ;.... r2 = 0,1 ;.... ¤1 = 0,05 ;.... ¤2 = 10^-6 = 0,000001;
u tom slucaju
dobivamo Q'2max = 0,02.
Mozemo takodjer pogledati, sto bi proizlaslo iz stvarno dobivenih podataka:
U ispitivanju
1. postignuto je sest rezultata p<0,000001 =¤2 (dakle: r2 = 6), a nepoznata je vrijednost r1 t.j. broj rezultata znacajnih
na razini ¤1 = 0,05. Ako je u 19 brojeva Lijecnickog vjesnika (u ispitivanju 2.) bilo 116 objavljenih rezultata p<0,05
(koji NISU svi dobiveni u medjusobno nezavisnim pokusima!), tada bi se u desetak brojeva (iz primjera 1.) moglo ocekivati
oko 60 takvih rezultata (tocnije: 61). Ako uzmemo u obzir sve tri godine (t.j. ukupno 36 brojeva Lijecnickog vjesnika u 1983.,
1984. i 1985. godini) ocekivali bismo oko 220 rezultata p<0,05. Uzmimo taj veci broj kao vrijednost r1 (premda bi stvarni
broj medjusobno nezavisnih rezultata bio valjda znanto manji!); dakle:
r1 = 220 (za razinu ¤1 = 0,05) ;......... r2 =
6 (za razinu ¤2 = 0,000001)
Ti su brojevi premaleni za izracunavanje Q'2max ali ipak mozemo doci do odgovora na pitanje
"je li razina ¤=0,000001 dovoljno visoka da se moze odbaciti nul-hipoteza u pojedinacnom pokusu", i to na slijedeci nacin:
Pretpostavimo da bismo u vrlo velikim skupovima (teoretski: neizmjerno velikim) nasli omjer r2/r1 = 0,0004 (odnosno
r1/r2 = 2500). U tom slucaju, vjerojatnost (P') da neki rezultat, koji je znacajan na nizoj razini (¤1 = 0,05), bude slucajno
takodjer znacajan i na visoj razini (¤2 = 0,000001), iznosi takodjer 0,0004. Ali, uz tu vjerojatnost je "prakticki nemoguce"
dobiti vise od pet znacajnih rezultata na visoj razini u 220 "POKUSAJA" (t.j. u 220 rezultata znacajnih na nizoj razini ¤1=0,05).
(Vidi nize: objasnjenje! *). Buduci da smo u 1. ispitivanju nasli sest znacajnih rezultata na visoj razini, spomenuta vjerojatnost
P' mora biti veca, dakle: P'>0,0004 a to znaci da je i r2/r1>0,0004 odnosno r1/r2<2500. Odatle proizlazi, prema formuli
(2), da je Q'2max < 0,05 . Prema tome, u velikom broju otkrica ucinjenih na razini ¤2 = 0,000001 biti ce manje od 5% laznih
otkrica, pa mozemo zakljuciti da je ta razina dovoljno visoka da opravda odbacivanje nul-hipoteze u pojedinacnom pokusu.
Ipak,
taj bi zakljucak trebalo jos bolje provjeriti !!! Bilo bi zanimljivo, na pr., pregledati veci broj znanstvenih casopisa i
odabrati (slucajnim izborom) znatno veci skup rezultata »p<0,05« te provjeriti koliko bismo medju njima nasli rezultata
»p<0,000001«.
*) Objasnjenje: Ako odaberemo (slucajnim izborom) jedan rezultat znacajan na nizoj razini (0,05)
tada postoji neka vjerojatnost P' da je on znacajan i na visoj razini (0,000001), a taj slucajni izbor manje znacajnog rezultata
je ustvari jedan POKUSAJ da se nadje takav visoko znacajni rezultat. Vjerojatnost P' jednaka je proporciji visoko znacajnih
rezultata u vrlo velikom skupu manje znacajnih rezultata a to je proporcija r2/r1 ; dakle: P'= r2/r1 (za vrlo velike skupove
r2 i r1).
Iz binomne raspodjele proizlazi, da se uz pretpostavljenu vjerojantost (P'=0,0004 za pojedini pokusaj) prakticki
ne moze dobiti sest ili vise spomenutih rezultata u 220 pokusaja.
Naime, vjerojatnost da se dobije vise od pet takvih
visoko znacajnih rezultata u 220 pokusaja
iznosi 5,6×10^-10. Buduci da se je ostvarilo to, sto je "prakticki nemoguce"
pri vjerojatnosti P'=0,0004 , zakljucujemo da ta vjerojatnost mora biti veca; dakle mora biti istinito da je P'>0,0004
a takodjer i P'= r2/r1 > 0,0004 (za vrlo velike skupove r2 i r1 , za kakve upravo i vrijedi formula (2), a to znaci da
se moze izracunati Q'2max):
Q'2max = [(r1/r2)-1]/[(¤1/¤2)-1] .................(2)
r1/r2 = 1/0,0004 = 2500
Q'2max
= [2500-1]/[(0,05/10^-6)-1] = 0,05
************
(OVE OSOBNE STRANICE NISU GOTOVE, NEGO SU JOS U IZRADI).
************
(NASTAVAK JE NA 4. STRANICI).
4. stranica
|
